On android, touch event is composed of a series events.
First, user puts his finger on an element, and the element receives a ACTION_DOWN event.
Then, while holding finger on screen, user moves his finger to a new location. The element receives a series of ACTION_MOVE events.
Finally, user raises his finger. At this point, the element receives ACTION_UP event.
Consider the figure below, the parent element has a child element inside. User can drag the child element anywhere in parent.

There are two important traits of touch event on android.
First, touch event will be propagated. That is, if a child chooses to ignore the first event (ACTION_DOWN) by returning false in its onTouchEvent handler, the parent's onTouchEvent handler will receive the event. Unless one of the ancestors agrees to handle the event or the root is reached, the event will continually be propagated.
Second, parent can intercept the touch event before its child's onTouchEvent handler is fired. This is achieved by overriding the onInterceptTouchEvent method on parent, and returning true from it. As a consequence, the child's onTouchEvent handler will be bypassed, and the parent's onTouchEvent handler will fire.
The work flow is shown in below diagram:
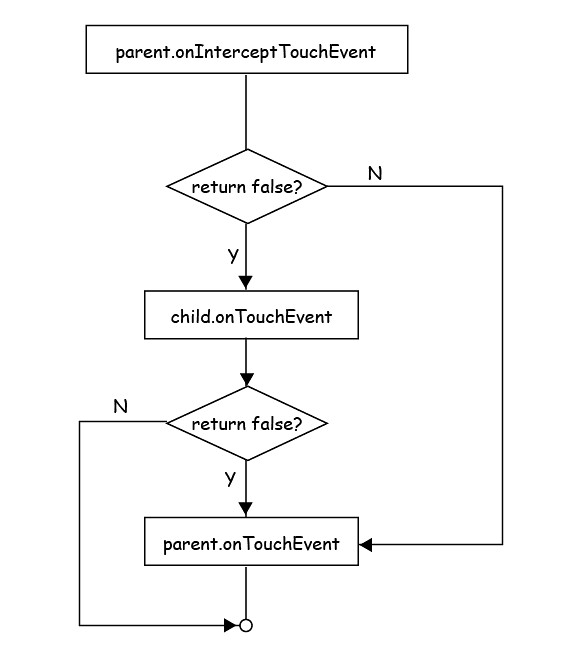
We need to setup the onTouchEvent handler for both child and parent. In child's handler, we save the child element as the item to be dragged, and return false so that subsequent event will be delivered to parent's handler. In parent's handler, we change the child's margin to match the position of the finger, so the child will follow our finger.
Sample code:
http://code.google.com/p/rxwen-blog-stuff/source/browse/#svn/trunk/android/drag
Reference:
http://developer.android.com/guide/topics/ui/ui-events.html




